Many Modalities,One Embedding Space
Jina v5 Omni on Elastic — multimodal and multilingual retrieval in a single index
The challenge
Search Stacks Multiply With Every Modality
Modern catalogs and customer signals arrive in text, photos, voice, and video.
- Shoppers type, upload photos, record voice notes, and watch product video.
- Classic stacks need a separate model and pipeline per modality — and another for cross-language coverage.
- Integration, latency, embedding drift, GPU cost, and operational toil compound as modalities accumulate.
- By the time you're shipping, the model landscape has moved again.
What if one embedding space handled all of it — inside your existing Elasticsearch query path?
Capability
Introducing Jina v5 Omni
A single model that embeds text, images, audio, and video into one vector space — across roughly 100 languages.
Text
Image
Audio
Video
~100 languages
1024-dim (small)
Available today via the Elastic Inference Service (EIS)
Managed endpoint inside your Elastic project — no model hosting, no GPU provisioning on your side. Inference IDs: .jina-embeddings-v5-omni-small and .jina-embeddings-v5-omni-nano
Why it matters
One Embedding Space, One Query Path
The traditional stack
- Text encoder + image encoder + speech model + video pipeline
- Separate indices and ranking strategies per modality
- Separate translation tier for non-English queries
- Drift across models when any one is upgraded
With v5 Omni on Elastic
- One model, one inference endpoint, four modalities
- Standard
semantic_text fields, standard query DSL
- Cross-lingual coverage out of the box
- Reuses your existing aggregations, filters, RBAC, snapshots
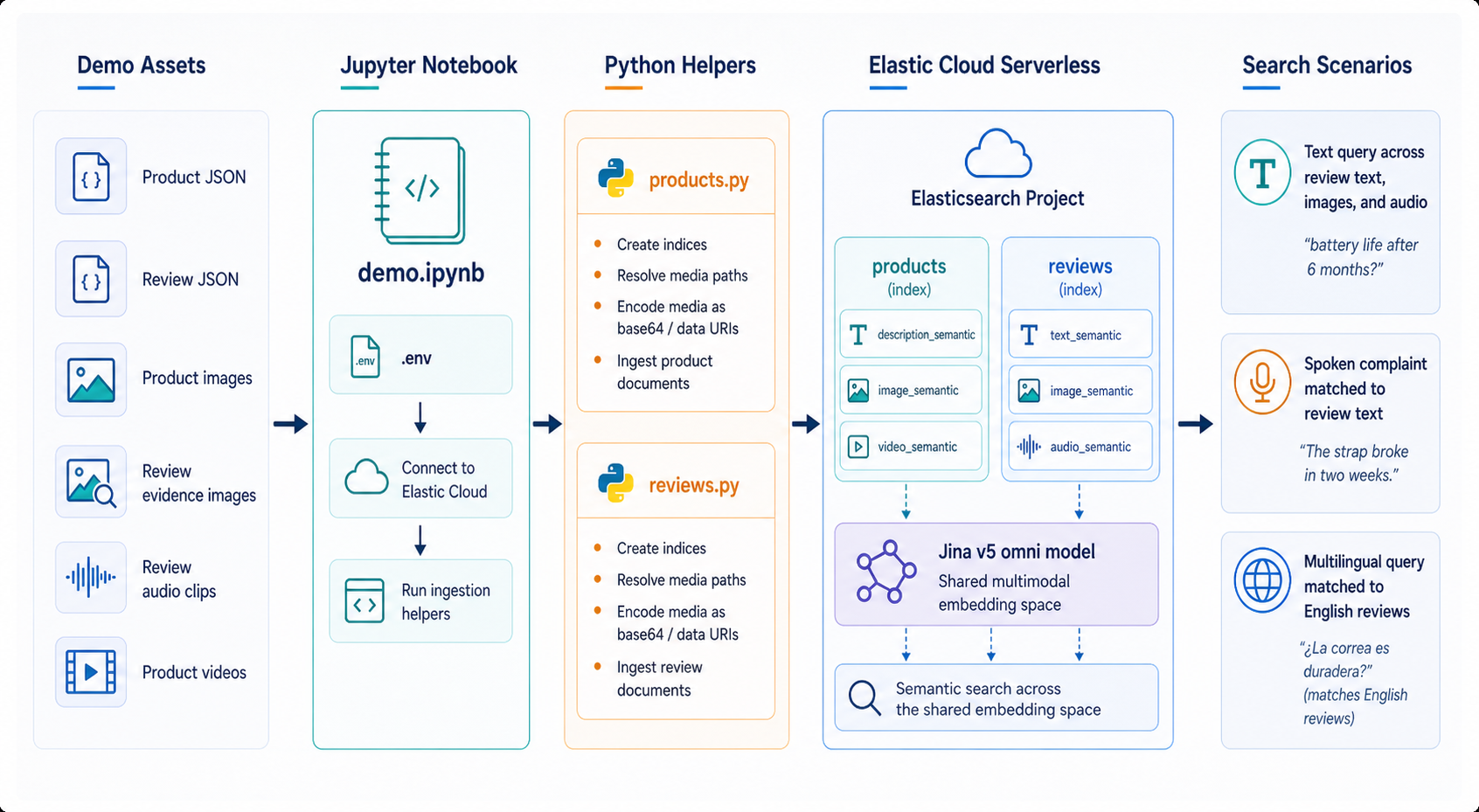
Demo architecture
Notebook-Driven, Fully Managed
Jupyter drives Terraform → Elastic Cloud Serverless. EIS hosts the model. Ingest and query flow through standard Elasticsearch APIs.
The dataset
Small Synthetic Ecommerce Catalog
Six products (three headphones, three sneakers) and six reviews. Each product carries text, image, and optional video. Each review carries text, audio, and an optional evidence image.

Auralite X1 — Black

BassCore Pro Max

StrideFlex — Black

StrideFlex — White
Indexed across two indices: products and reviews.
Index design
One Inference ID, Many Fields
Each modality gets its own semantic_text field, all wired to the same EIS-managed inference endpoint. The mapping is strict; media bytes are sent as base64 data URIs.
"properties": {
"description": { "type": "text", "copy_to": "description_semantic" },
"description_semantic": { "type": "semantic_text",
"inference_id": ".jina-embeddings-v5-omni-small" },
"image_semantic": { "type": "semantic_text",
"inference_id": ".jina-embeddings-v5-omni-small" },
"video_semantic": { "type": "semantic_text",
"inference_id": ".jina-embeddings-v5-omni-small" }
}
No bespoke ingest pipeline. EIS handles the embedding at index time and at query time.
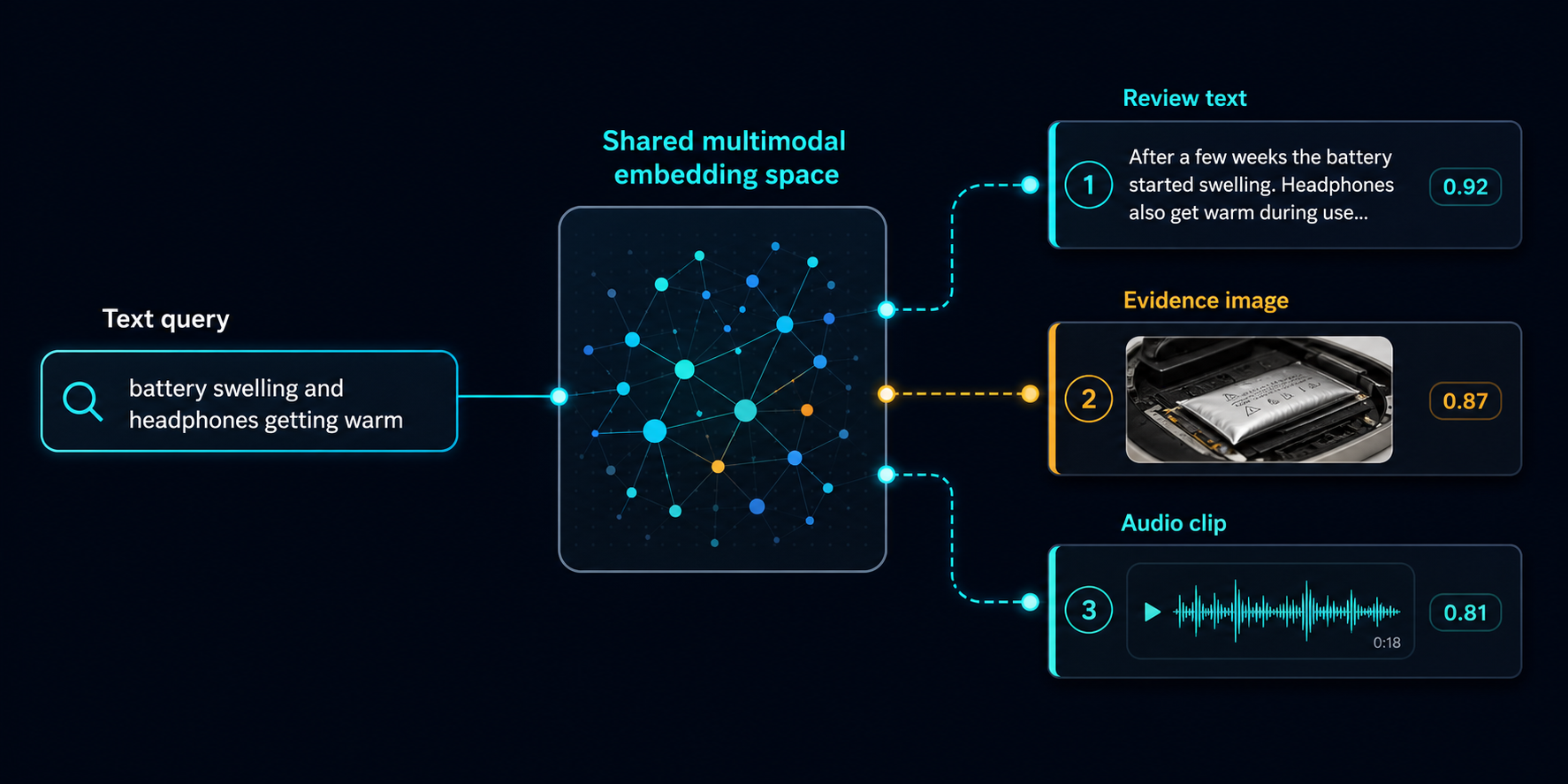
Scenario 1
Text Query → All Review Modalities
- One text query fans out to
text_semantic, image_semantic, and audio_semantic.
- Same embedding ranks each field independently — no transcription, no captioning.
- Demonstrates the shared embedding space directly.
Text query: battery swelling and overheating
--- Review text ---
0.878 r1 (hp_001): battery started swelling…
--- Review image ---
0.609 r1 (hp_001): battery started swelling…
--- Review audio ---
0.619 r2 (hp_001): amazing sound quality…
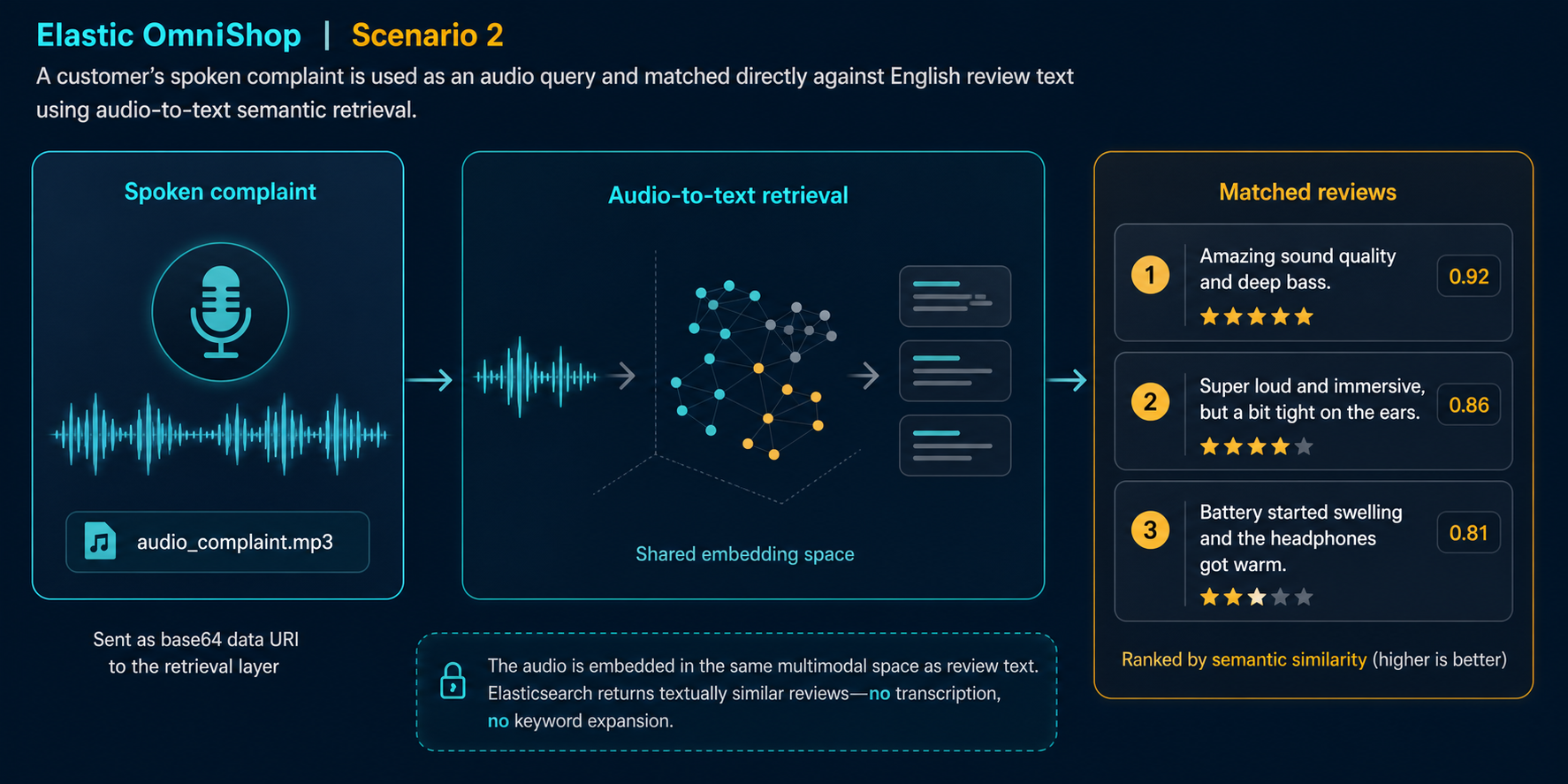
Scenario 2
Audio Complaint → Review Text
- Customer voice clip sent as a base64 data URI directly to
text_semantic.
- Model embeds the spoken complaint into the shared space — no Whisper sidecar, no transcription step.
- Top results are all headphone reviews — the model correctly clusters the audio with related text.
Audio query: audio_complaint.mp3
0.706 Auralite X1 (hp_001) — r2: sound quality…
0.665 BassCore Pro Max (hp_003) — r3
0.632 Auralite X1 (hp_001) — r1: battery defect
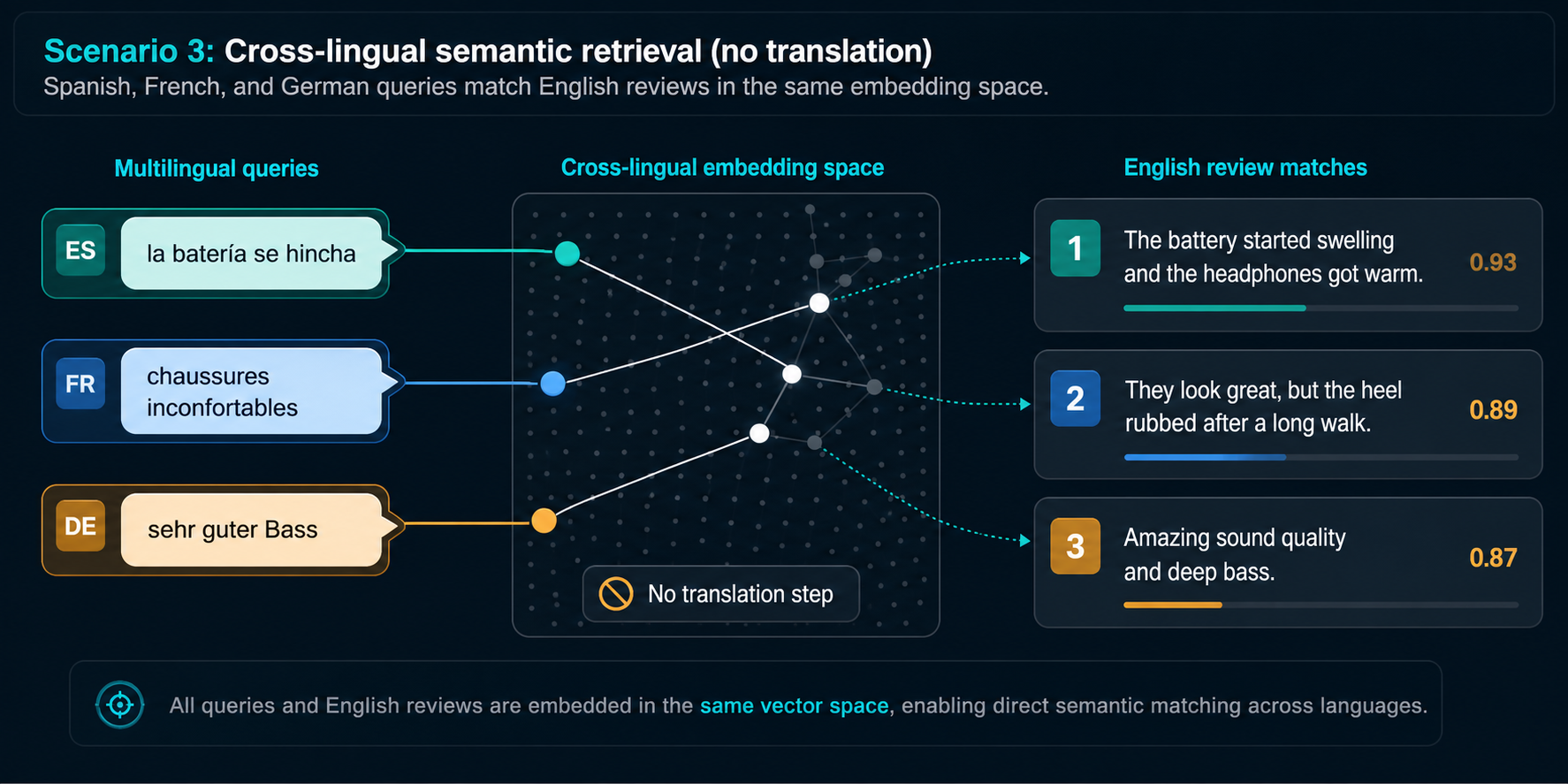
Scenario 3
Multilingual Text → English Reviews
- Queries in Spanish, French, German match English review text directly — no translation tier.
- One embedding space spans roughly 100 languages.
- Cross-lingual coverage without paying for a separate translation pipeline.
Spanish: auriculares con problema de batería que se hincha
0.869 r1 (hp_001): battery started swelling…
French: la couleur des chaussures s'est décolorée…
0.851 r4 (sn_001): color faded after a few runs
German: großartiger Klang und tiefer Bass
0.846 r2 (hp_001): deep bass, sound quality
Operations
What Your Platform Team Inherits
- Elastic Inference Service hosts the model. No GPU procurement, no inference container ops, no model rollouts on your side.
- Single
semantic_text query pattern for every modality — your existing search code learns one new field type.
- Standard Elastic stack still applies: filters, aggregations, vector + BM25 hybrid, RBAC, snapshots, ILM, Kibana observability.
- Terraform-managed projects — the same code path from POC to staging to production.
- Multi-cloud, serverless-first — sized to demand, paid by usage, no clusters to babysit.
Business outcome
Why Customers Choose This Path
Time-to-market
Stand up a multimodal search prototype in days, not quarters. The same notebook in this demo is the starting point.
Lower TCO
One embedding stack and one inference contract replace separate per-modality model pipelines.
Wider market reach
~100-language coverage without translation infrastructure — open up regional markets without rebuilding search.
Future-proofing
Model evolution managed by Elastic and Jina. Swap the inference ID, keep the index and query code.
Next steps
Resources & Q&A
Everything in this deck is reproducible. The full demo runs end-to-end from one notebook.
Demo repository
github.com/joeywhelan/omnishop
Companion article
Many Modalities, One Embedding Space — full walkthrough
Elastic Inference Service
elastic.co/docs/explore-analyze/elastic-inference/eis
Elastic Cloud Serverless
elastic.co/cloud/serverless
Let's talk about the modalities in your search workload.