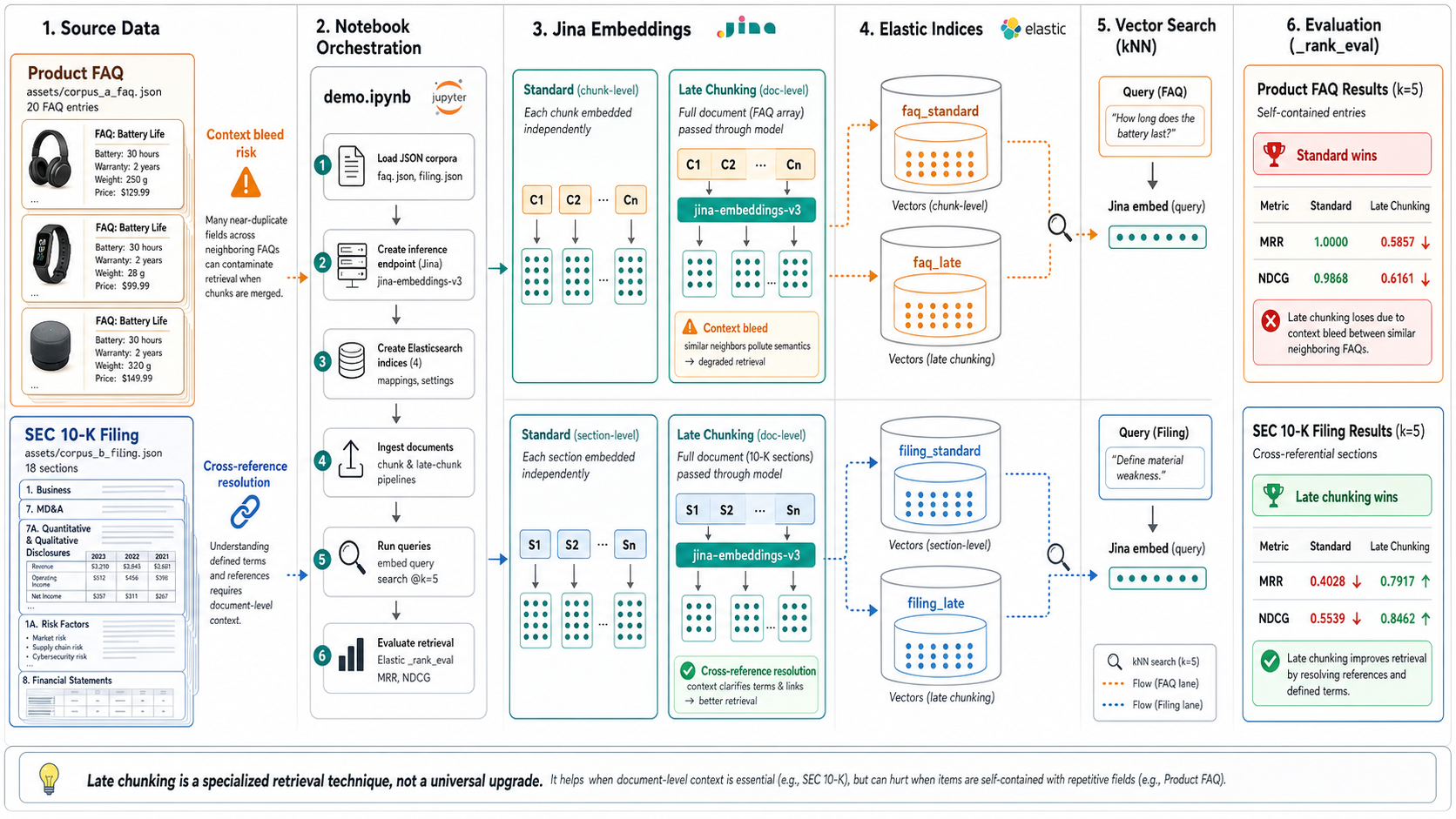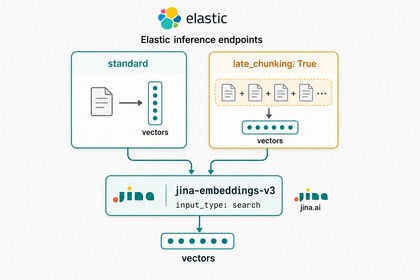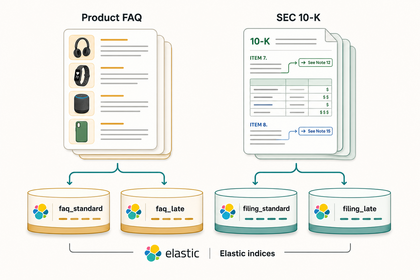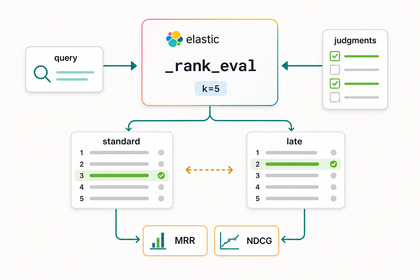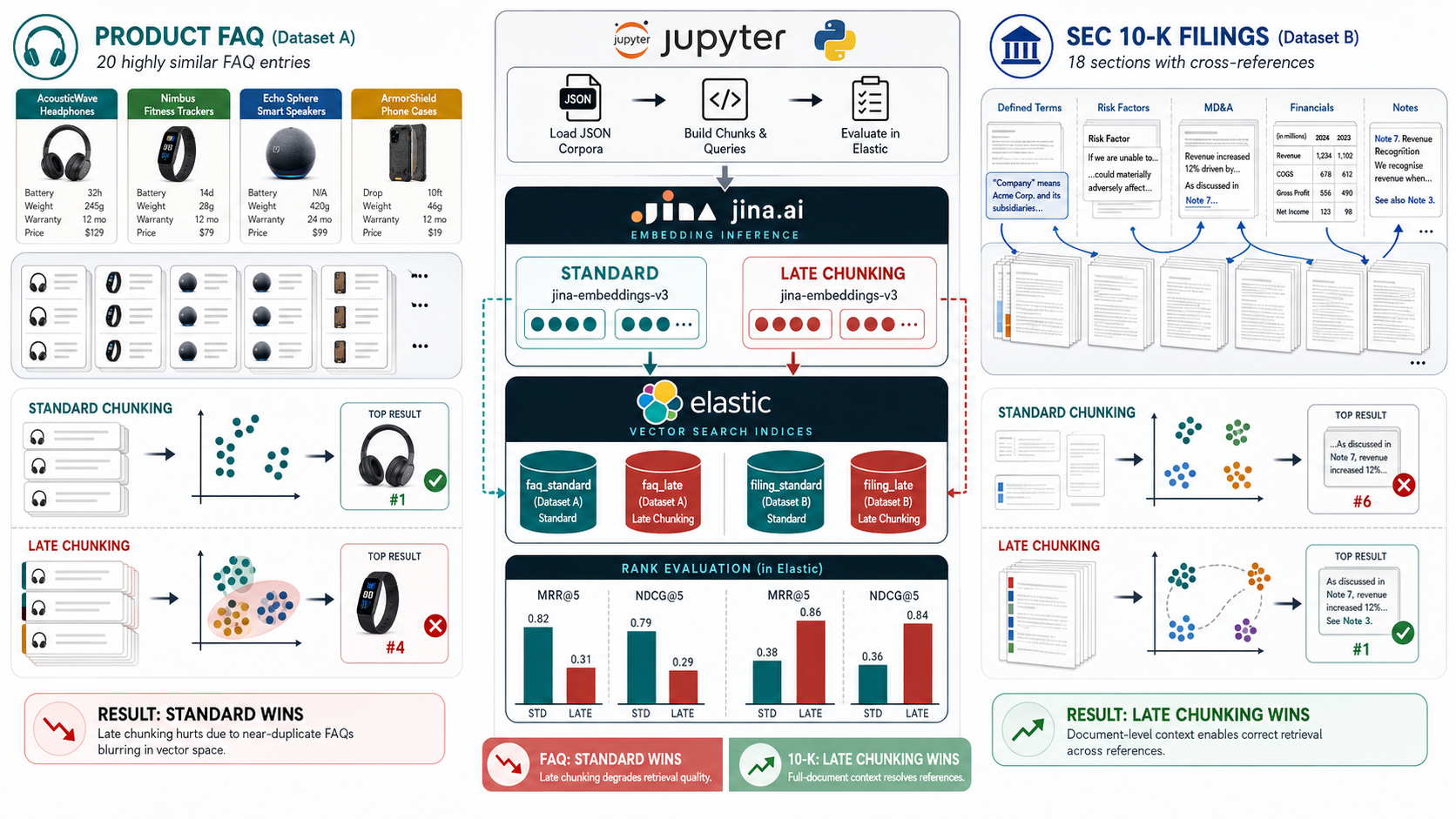
Every RAG and semantic-search pipeline splits documents into chunks, then embeds each chunk into a vector. The conventional approach embeds each chunk in isolation.
A newer technique — late chunking — embeds the whole document first, then derives per-chunk vectors from that shared context.
The promise
Each chunk's vector "remembers" the surrounding document — pronouns, defined terms, and references resolve correctly.
The catch
It is widely presented as a universal upgrade. Our experiment shows it isn't. Sometimes it helps a lot. Sometimes it actively hurts.