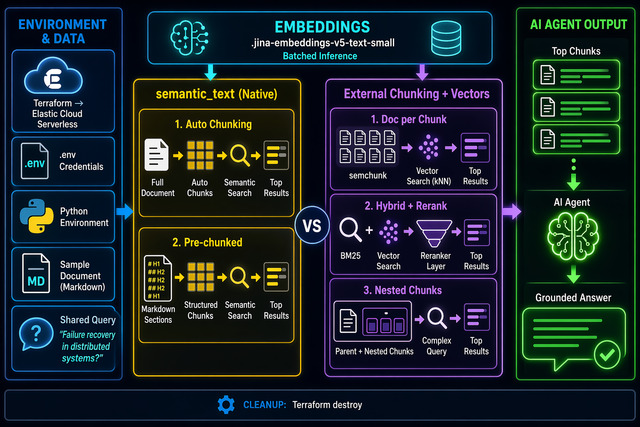
Why Chunking Matters
Document chunking breaks large documents into smaller segments before converting them to vectors for storage and retrieval.
This aids an agent by pinpointing the exact excerpt needed to answer a query — rather than retrieving the entire document.
The alternative — vectorizing the whole document — means important details get washed out by surrounding context. Signal is lost.
Architecture
- All logic executed from a Jupyter notebook
- Elastic Serverless as the vector platform — provisioned via Terraform
- Single sample markdown document —
sample_doc.md— 2,427 words - Shared query: "How do distributed systems handle failures and recovery?"
- Embedding:
.jina-embeddings-v5-text-small(1024 dims · EIS)
Four Strategies
-
1Semantic Text — Automatic Chunking ES handles chunking, embedding, and retrieval. Zero pipeline overhead.
-
2Semantic Text — Pre-chunked Arrays Application controls chunk boundaries; ES still manages embedding.
-
3External Chunking — One Document Per Chunk Each chunk is an independent ES document with
dense_vector. -
4External Chunking — Nested Chunks Chunks stored as nested objects inside the parent document.
Semantic Text — Automatic Chunking
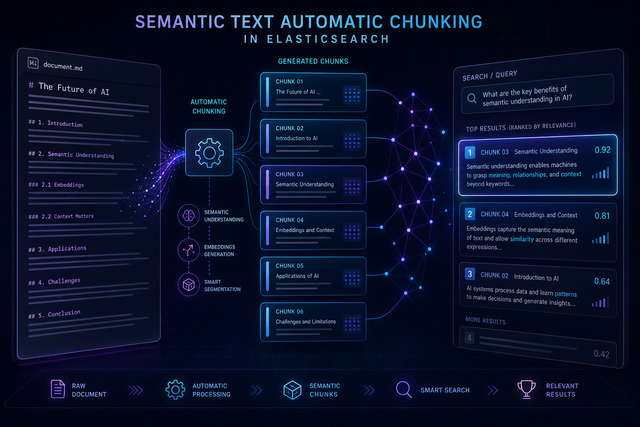
Index the raw document as a single string. Elasticsearch automatically:
- Splits into chunks via the recursive strategy, aligned to markdown headings
- Generates embeddings via
.jina-embeddings-v5-text-smallon EIS - Stores chunks internally per document
- Returns ranked chunks via highlighting
Mapping & Ingest
scenario1_mapping = {
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"chunking_settings": {
"strategy": "recursive",
"max_chunk_size": 200,
"separator_group": "markdown"
}
}
}
}
}
es.indices.create(index=S1_INDEX,
body=scenario1_mapping)
es.index(index=S1_INDEX, id=1,
document={"content": doc_content})18 chunks auto-produced — aligned to markdown headings. No external library. No local inference.
Search & Results
response = es.search(
index=S1_INDEX,
body={
"query": {
"semantic": {
"field": "content",
"query": QUERY,
}
},
"_source": False,
"highlight": {
"fields": {
"content": {
"type": "semantic",
"number_of_fragments": 5,
"order": "score",
}
}
},
"size": 5
},
)Top-5 chunks returned in relevance order
Appraisal
✓ Pros
- Simplest implementation — index raw text, ES does the rest
- Zero pipeline overhead — no external libraries or local inference
- Configurable via
chunking_settings - Highlighting returns chunks ranked by similarity
- Compatible with hybrid BM25+vector search
✗ Cons
- No per-chunk metadata — can't attach tags or filters to individual chunks
- Chunks are internal — can't update or delete a single chunk without reindexing the whole document
⚡ Good For
- Rapid prototyping — working semantic search in minutes
- Teams without dedicated ML ops who want vector search out of the box
Semantic Text — Pre-chunked Arrays
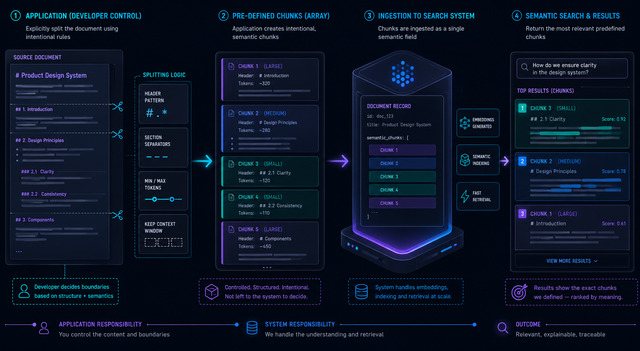
Disable ES auto-chunking with strategy: "none". Application pre-chunks the document and passes a chunk array to the semantic_text field.
ES still handles embedding and retrieval — no dense_vector or inference pipeline needed.
Chunking strategy: regex split on markdown headings (H1 / H2 / H3)
Code & Results
# Disable auto-chunking
mapping = {
"content": {
"type": "semantic_text",
"chunking_settings": {
"strategy": "none"
}
}
}
# Regex split on all markdown headings
chunks = re.split(
r'(?=^#{1,3} )',
doc_content,
flags=re.MULTILINE
)
chunks = [c.strip() for c in chunks
if c.strip()]
# → 24 chunks
# Pass chunk array to semantic_text
es.index(index=S2_INDEX,
document={"content": chunks})24 chunks — one per heading section
Appraisal
✓ Pros
- Application controls exact chunk boundaries
- ES still manages embedding — no local inference
- Same simple
semantic_textmapping as Strategy 1 - Highlighting retrieves the most relevant pre-defined chunks
✗ Cons
- No per-chunk metadata
- Can't independently update or delete a single chunk
- Chunking quality is your responsibility
- Each chunk must fit the inference model's token limit
⚡ Good For
- Documents with clear structural boundaries — markdown headers, HTML sections, paragraphs
- When you need chunking control without managing embedding infrastructure
External Chunking — One Document Per Chunk
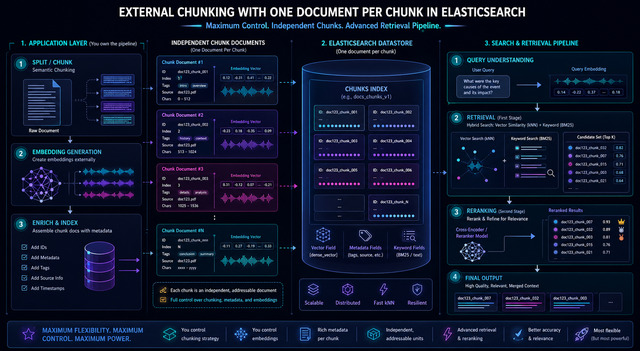
Each chunk is indexed as an independent top-level document with a dense_vector field.
- Chunking:
semchunklibrary (chunk_size=200) - Embeddings: Elastic Inference API
- Per-chunk metadata:
parent_id,chunk_index - Vector quantization:
int8_hnsw - Same index demonstrates hybrid search + reranking — no reindexing needed
Ingest & kNN Search
chunks = chunk(doc_content,
chunk_size=200,
token_counter=token_counter)
# → 15 chunks
# Batch embed via Inference API
result = es.inference.inference(
inference_id=EMBEDDING_MODEL,
task_type="text_embedding",
body={"input": batch}
)
# kNN search
response = es.search(
index=S3_INDEX,
body={
"knn": {
"field": "embedding",
"query_vector": query_embedding,
"k": 5,
"num_candidates": 20
},
"size": 5
}
)kNN results — top-5 chunks
Hybrid Search + Reranking
response = es.options(
request_timeout=120).search(
index=S3_INDEX, # same index as kNN
body={
"retriever": {
"text_similarity_reranker": {
"retriever": {
"linear": {
"retrievers": [
{"retriever": {"standard": {
"query": {"match": {
"chunk_text": QUERY}}}},
"weight": 0.3}, # BM25
{"retriever": {"knn": {
"field": "embedding",
"query_vector": query_embedding,
"k": 10}},
"weight": 0.7} # vector
]}},
"inference_id": ".jina-reranker-v3",
"inference_text": QUERY,
"field": "chunk_text"
}
}
}
)No reindexing required — query-level capability
★ Reranker surfaces Circuit Breakers (Chunk 8) — absent from pure kNN top-5
Appraisal
✓ Pros
- Each chunk is independent — update, delete, or reindex without touching others
- Per-chunk metadata for filtering
✗ Cons
- Requires an external chunking pipeline
- More moving parts — chunking library, embedding generation
- Chunk quality depends entirely on splitter configuration
⚡ Good For
- Agentic AI apps needing filterable, retrievable chunks with metadata
- Production systems requiring full control over model and retrieval
- Multi-document corpora
External Chunking — Nested Chunks
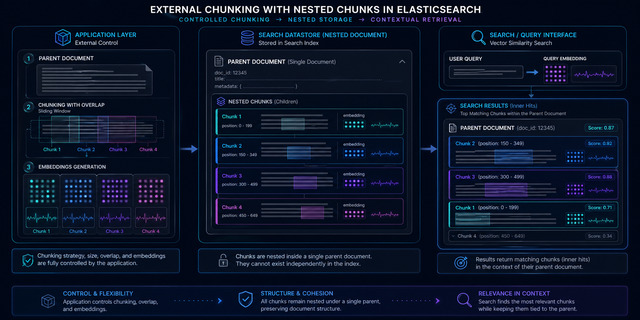
- Chunks stored as nested objects inside the parent — atomic indexing, strict cohesion
- Chunking: LangChain
RecursiveCharacterTextSplitter(chunk_size=800,chunk_overlap=100) - 28 chunks stored in one parent doc
- Parent and all chunks indexed/deleted as a single atomic unit
- Query via nested kNN with
inner_hits
Code & Results
response = es.search(
index=S5_INDEX,
body={
"query": {
"nested": {
"path": "chunks",
"query": {
"knn": {
"field": "chunks.embedding",
"query_vector": query_embedding,
"num_candidates": 20
}
},
"inner_hits": {
"size": 5,
"_source": [
"chunks.chunk_index",
"chunks.chunk_text"
]
}
}
},
"size": 1
},
)Parent document + matched inner hits
Appraisal
✓ Pros
- Document cohesion — chunks physically co-located with their parent
- Atomic indexing — parent and all chunks indexed/deleted as one unit
- Inner hits return matched chunks with scores while preserving parent context
✗ Cons
- Nested kNN queries are more complex and slower than top-level kNN
- Updating one chunk requires reindexing the entire parent
- Cannot independently filter or paginate chunks across documents
- Performance and doc size degrade as chunk count grows
⚡ Good For
- Small-to-moderate collections with modest chunks per document
- Document integrity is paramount
- Always retrieving chunks in the context of their parent
Conclusion
semantic_text provides the most automation — index raw text, Elasticsearch handles the rest. Start here.
dense_vector with external chunking gives full control — choose your chunker, your embedding model, and your retrieval strategy.